

Sora之后,OpenAI于北京时间5月14日凌晨推出“王炸”新模型GPT-4o。“o”代表“omni”,代表“全能”。
号称“全能”的确不假。GPT-4o不仅能够实时处理文本、音频和图像,还采用全新的语音交互模式,大幅提升人机对话的响应速度,几乎与真人对话相差无几,它还会看人脸色、讲笑话……总之,AI更像人,甚至更像一个朋友了。
在GPT-4o的“人性”背后,大模型正进入多模态发展的新阶段。模型不再追求长文本的单一的语言对话,视觉、语音乃至情感都成为模型参数中的关键。对如今的“百模大战”而言,这一变化是危机还是商机?
“聪明快速且自然”
作为ChatGPT的基础技术模型,GPT-4o的能力直接将影响ChatGPT的用户体验。“GPT-4o是OpenAI有史以来最好的模型,它既聪明又快速,是自然的多模态。”OpenAI CEO山姆·奥特曼没有出现在发布会现场,但给出了一句极高的评价。
GPT-4o有多聪明?
根据OpenAI的发布会和官网披露的信息所示,GPT-4o不仅可以识别手写字体,还能解答数学方程式,甚至还能识别图像中的人物微表情。
根据传统基准测试,GPT-4o的性能对比GPT-4 Turbo(OpenAI去年11月发布的大模型)基本都处于优势,对比其他模型更是大幅领先。具体来说,GPT-4o在英语文本和代码上的性能与GPT-4 Turbo类似,但在非英语文本上的性能显著提高,与现有模型相比,GPT-4o在视频和音频方面表现尤为出色。
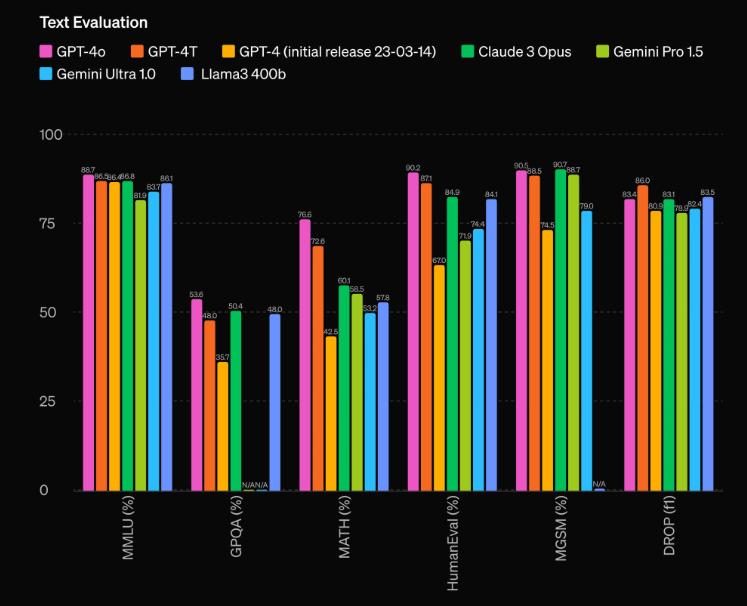 GPT-4o在基准测试中名列前茅。
GPT-4o在基准测试中名列前茅。
在“高智商”的加持下,GPT-4o的反应速度跳上了新台阶。
它最快能够在232毫秒内响应语音输入,平均响应时长约320毫秒,这大约与人类对话相当。如果对320毫秒的突破没有直观印象,不妨看看上一代模型的成绩:语音对话模式下,ChatGPT的平均响应时长为2.8秒(基于GPT-3.5)和5.4秒(基于GPT-4)。
GPT-4o之所以这么快,离不开全新的神经网络处理流程。
“我们现在常见的‘Siri’‘小爱同学’等语音助理,以及GPT-3.5等上代大模型对语音对话的处理能力慢,至少需要三个步骤,反应时间和处理速度延迟感强。”国内某AI企业技术专家解释称,第一步,音频转文本将人的指令转化为文本输入,第二步,机器文本理解并输出文本,第三部,文本转语音“说”给用户,这才完成了语音对话的流程。“这样的模式不仅慢,而且会遗漏许多语音中的信息熵值,也会影响对话的连贯性。”
在 GPT-4o 上,OpenAI 跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一模型内处理,实现真正的多模态交互。
高智商叠加反应快,GPT-4o还模仿了人类的情感和幽默感,更具人情味。难怪山姆·奥特曼称之为“人类级别的响应”。
基于GPT-4o的天赋,ChatGPT不仅能实时语音对话,还能听懂用户对话的不同语气和情绪状态,还能相应生成不同的情感表达,甚至可以要求GPT-4o唱歌,对话时几乎感受不到僵硬的AI感。
经过OpenAI的现场展示,不少人认为,会提供情绪价值的“AI伴侣”已触手可及。
国内模型存在代际差异
“现在主打情感陪伴的AI创业公司可以退场了。”惊讶于GPT-4o强大共情能力,不少细分AI赛道隐隐感受到了危机。
此前,ChatGPT主要追求性能和生产力,不少创业公司错位竞争,打造了一批“类人”AI产品,也吸引了部分用户。比如Inflection.AI的AI机器人Pi诞生一年就收获了百万级别的日活用户。国内大模型公司MiniMax推出一款名为Glow的虚拟聊天产品,仅四个月时间也吸引了数百万用户。
不同于Pi等纯陪伴型的机器人,GPT-4o既能当帮手,还能开玩笑的“多面手”,无形中提高了AI的创业门槛。
“GPT-4o使得市场对AI产品的期望值大幅提高,创业公司需要投入更多资源来开发和优化其AI模型。”上海市人工智能行业协会秘书长钟俊浩表示,如 OpenAI、谷歌、苹果等大公司,能够更快地推出高性能AI模型,导致市场资源向这些大公司集中,初创公司难以获取足够的市场份额和投资。
不仅是创业公司,国内的AI巨头的压力也不小。
目前,国内AI在多模态模型训练方面主要采用图像和文字联合训练,语音则是通过单独的模型进行处理并拆解完成的上下游任务。与GPT-4o高度拟人化的多模态联合训练相比,仍存在代际差距。
“据我了解,目前,国内如上海人工智能实验室、字节跳动、阿里和Minimax等企业也在进行类似的多模态联合训练研究,但很难说已经有能够匹敌GPT-4o的产品。”不过,他同时也表示出乐观,凭借国内巨头研发能力,追赶GPT-4o并非遥不可及,在国内算力基础设施日益完善的前提下,“平替”产品的研发周期会大幅缩短。
据记者了解,商汤近期推出了商量拟人大模型“SenseChat-Character”,支持个性化角色创建与定制、知识库构建、长对话记忆、多人群聊等功能,可实现行业领先的角色对话、人设及剧情推动能力,可以广泛应用于情感陪伴、影视动漫IP角色、明星网红AI分身、语言角色扮演游戏等拟人对话场景。
 商量拟人大模型“SenseChat-Character”
商量拟人大模型“SenseChat-Character”
多模态交互是大势所趋
“大模型发展一年以来,能力快速上升的同时,发展趋势也更加清晰。”阿里云首席技术官周靖人认为,从单一语言模型到多模态混同发展是大势所趋。
多模态模型,通常指能同时处理和整合多种类型数据(如文本、图像、声音等)的大模型,GPT-4o的横空出世便是多模态模型的集大成。
国内也在争取抓住多模态的东风,也取得了斐然的成绩。
据第三方统计,2023年,国内多模态AI概念股研发支出合计达到327.53亿元,占营收比例为11.2%,这一比例是同期A股整体水平的4.46倍。云从科技-UW、格灵深瞳、阿尔特虹软科技4只概念股研发支出占营收比超过50%,相当于拿出超一半的营收投入研发。
5月9日,阿里云发布的通义千问2.5,其多模态模型已初具影响力,如视觉理解模型Qwen-VL-Max在多个多模态标准测试中超越Gemini Ultra和GPT-4V,目前已在多家企业落地应用。当前,通义已发展出文生图、智能编码、文档解析、音视频理解等能力。
 通义千问2.5正对标GPT-4.
通义千问2.5正对标GPT-4.
14日,腾讯也宣布旗下混元文生图大模型全面升级,升级后采用了与Sora一致的DiT架构,不仅可支持文生图,也可作为视频等多模态视觉生成的基础。评测数据显示,混元文生图模型整体能力属于国际领先水平。
作为OpenAI的春季升级产品,GPT-4o在多模态上的出色表现,更让业界对即将到来的GPT-5产生浓厚兴趣。
钟俊浩预计,GPT-5在多模态的基础上将进一步强化多模态交互中的表现,不仅能够处理文本,还能通过摄像头、麦克风等设备直接与现实环境互动。例如,通过摄像头识别物体并执行相应的指令,这将大大提升AI在现实场景中的实用性和交互体验。同时,GPT-5还可与第三方凭他无缝整合,例如智能家居设备及办公系统等,以扩展其应用场景。
这也给AI创业公司带来了新商机。“创业公司不妨利用OpenAI提供的API(编程接口)来增强其产品功能,在垂直领域找到与科技巨头的互补点,或针对特定行业或用户需求,开发定制化解决方案。”钟俊浩建议。
栏目主编:李晔
本文作者:查睿