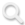转载自:上观新闻
近日,MiniMax国产大模型,上海稀宇科技有限公司研发的基础语言大模型 MiniMax-Text-01和视觉多模态大模型 MiniMax-VL-01已入驻超算互联网AI开源社区。
作为国产大模型系列,MiniMax覆盖文本、语音、图像和视频领域,凭借自主研发的模型架构在长文本处理、多模态融合等方面性能优越。今年初发布并开源的新一代系列模型MiniMax-01首次将线性注意力机制扩展到商用模型级别,综合能力跻身全球第一梯队。特别是在“上下文长度”这个指标上,它达到了国内外一些顶尖模型的20—32 倍水平,推理时的上下文窗口能达到400万token(词元)。
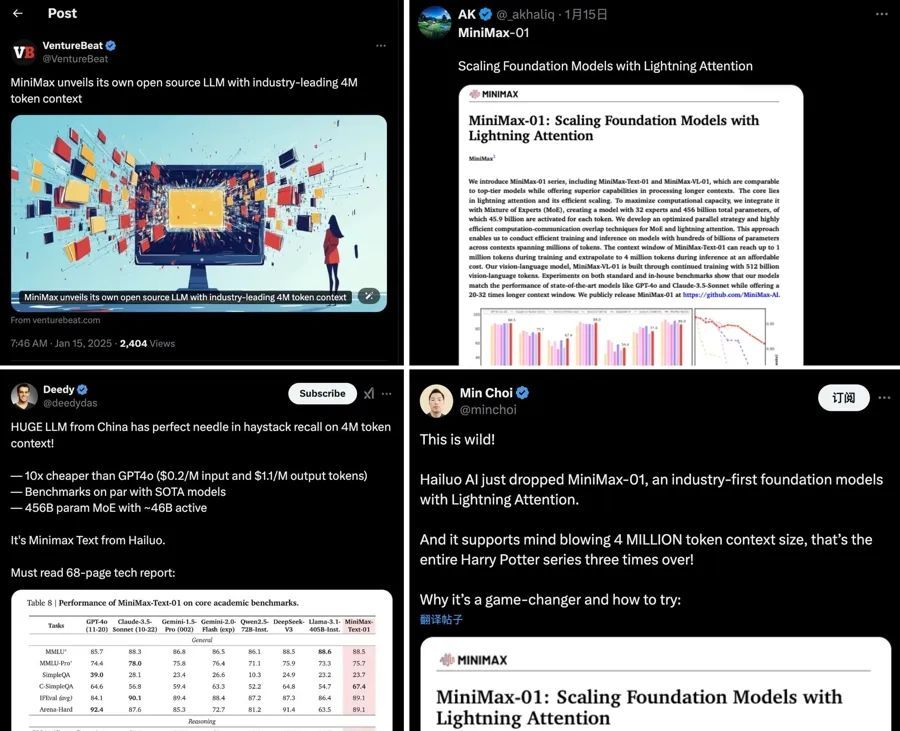
“放眼国内外的大模型,‘大脑’虽大,但‘记忆力’往往不够用。”MiniMax研发负责人说,“如果让大模型理解一份长达1000页的法律合同、一部长篇小说或一个几十万行的源代码项目,并给出准确的摘要、发现潜在风险、提出结构化建议,大多数大模型都无法完成任务,因为它们连读完材料也做不到,更不用说音视频等多模态信息处理了。而MiniMax-01可以做到,因为它的上下文窗口约为700万字,相当于一下子读完中国四大文学名著和哈利波特全集。”
在架构上,MiniMax-Text-01几乎重构了训练和推理系统,模型的参数量高达4560亿,每次激活459亿。在注意力机制层面,它的80个注意力层有架构创新,使大模型在处理长输入时在确保处理效果的同时做到了低延迟。
基于基础语言大模型,研发团队还开发了多模态大模型MiniMax-VL-01。它不仅继承了文本处理的高效性,还具备很强的视觉理解能力,在多种视觉语言任务基准测试中展现出与顶尖模型相媲美的性能。
随着越来越多的智能体(Agent)进入应用场景,无论是单个智能体工作时产生的记忆,还是多个智能体协作产生的上下文,都会对大模型的上下文窗口长度提出更高要求。因此,长上下文能力与多模态处理能力的提升,有助于智能体为各行业带来更丰富、高效的解决方案。
入驻国家超算互联网平台后,MiniMax将与国家级算力服务平台携手推动国产大模型技术发展,促进更多应用开发者开展突破性研究。
欢迎转发,但请注明出处“上海经信委”
觉得不错请点赞!